抓圖高手
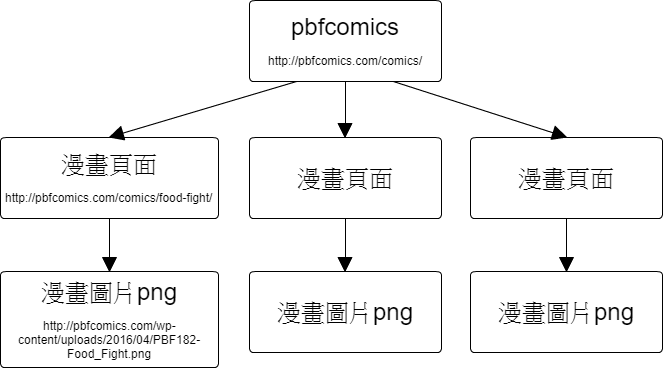
我們再回頭來複習爬蟲,之前的爬蟲都只爬一整頁,不會抓取內文的資料,也不會換頁,這次進一步使用遞迴的方式來實作爬蟲,把整個網站的圖片都載下來。

爬蟲流程:
程式碼架構
var fs = require('fs'),
request = require('request'),
cheerio = require('cheerio'),
async = require('async');
var imgDir = './images';
if (!fs.existsSync(imgDir)) {
fs.mkdirSync(imgDir);
}
//===========================================
var getImgList = function (url, callback) {
var links = [];
request(url, function (err, res, body) {
if (!err && res.statusCode == 200) {
var $ = cheerio.load(body);
//TODO: get each url of img, and save it to links
$('包含網址的DOM').each(function (index, element) {
//use $(element) to do something
});
callback(links);
};
});
}
//===========================================
var getImgs = function (webUrls, callback) {
//i代表已拜訪的網站數量,j代表以下載的圖片數量
var i = 0, j = 0;
//將整個陣列的網依依執行下載圖片
async.map(webUrls, function (imageUrl, cb) {
request(imageUrl, function (err, res, body) {
//TODO 用cheerio取得網頁中的圖片連結
//這邊可以加 ++i
request('圖片連結放這').pipe(fs.createWriteStream(imgDir + '/圖片名稱.png')).on('finish', function () {
//這邊可以加 ++j
//已經下載好該圖片,接著cb(err,result),第一個值是error,所以沒error就填null,第二個值是要回傳給最後一個function的值
cb(null, 'pbfcomics' + i + '.png');
});
});
}, function (err, results) {
//整個陣列都處理完了
callback(results);
});
};
//===========================================
//主程式
getImgList('http://pbfcomics.com/comics/', function (links) {
console.log("there are "+links.length+" imgs to download!");
getImgs(links, function (result) { });
});
在command line不換行輸出文字
process.stdout.write("這樣輸出就不會換行了\r");
async套件
我們要讓對每個網站連結做http request,但是request最好使用非同步的方式實作,不然等一個http request做完再做下一個就太浪費時間了,所以以我們在這邊使用一個叫做async的套件,async.map的用法如下。
第一個function就是對陣列中每個項目的處理,第二個function就是整個陣列都處理完之後會執行,收入大家callback的結果。
var async = require('async');
var ary = [1,2,3,4,5,6,7,8,9,0];
async.map(ary, function (item, callback) {
//array中的每個項目item會被取出,可以在這邊對item做處理
console.log("陣列項目:"+item);
callback(null,item*item);
}, function(err, results){
console.log("輸出結果:"+results);
});
輸出結果如下
陣列項目:1
陣列項目:2
陣列項目:3
陣列項目:4
陣列項目:5
陣列項目:6
陣列項目:7
陣列項目:8
陣列項目:9
陣列項目:0
輸出結果:1,4,9,16,25,36,49,64,81,0
課堂練習
試試看其他的漫畫網頁,把它一次載下來吧!

![]()
不過這兩個網站的抓法又不同了,這次試著用遞迴,讓網站從最新的圖片,開始抓,接著讓爬蟲爬到前一頁繼續抓,一直抓到沒有前一頁為止,其實沒有很難,我們來試試看吧!一起當抓圖高手。